Learning in the Frequency Domain (CVPR 2020)
Highlight
通过压缩神经网络的输入, 增大输入图片的尺寸, 从而提升视觉任务的性能.
文章链接: arXiv
代码链接: GitHub
作者信息:
Kai Xu, Minghai Qin, Fei Sun, Yuhao Wang, Yen-Kuang Chen, Fengbo Ren
DAMO Academy, Alibaba Group
Arizona State University
Overview
由于GPU设备Memory的限制, 当前视觉任务模型中, 输入图像的尺寸较小. 这限制了模型性能, 本文提出了一种通过图像压缩的方法, 来增大深度神经网络实际的输入图像尺寸的方法. 具体实现是在频率域上对图像进行频域变换, 然后将图像的频域特征输入给神经网络. 然后使用了一种结合了重参数化方法的SE block的模块自适应地学习哪些频率对于特定的视觉任务比较有效. 最后, 基于在数据集层面的统计特征, 选出最有效的 N个频率, 丢掉其余频率的数据, 实现对输入数据的压缩, 并且不会有性能损失. 文章展示并验证了通过压缩的方法将输入图像的尺寸变大, 从而实现最终性能提升的思路.
Method
Data Pre-processing in the Frequency Domain
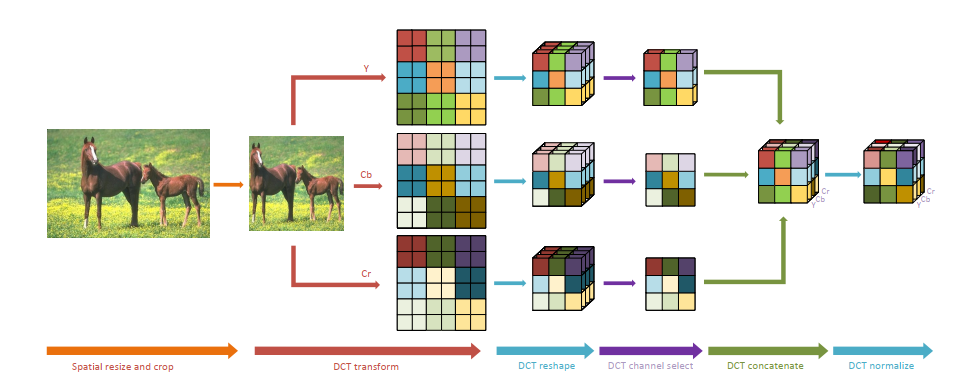
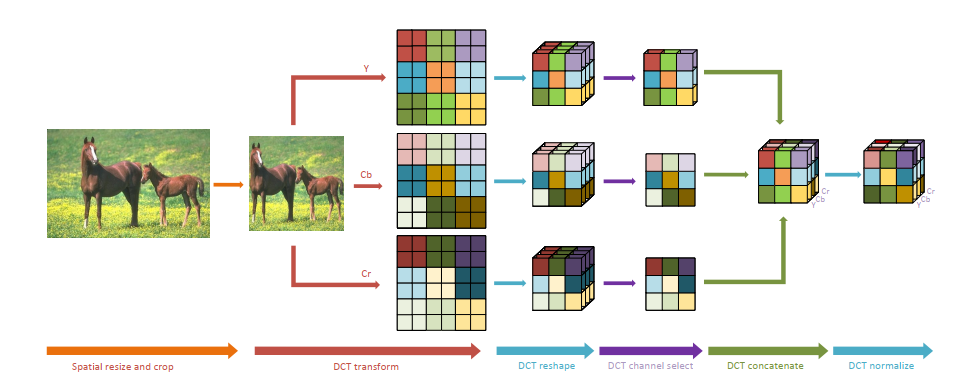
图像输入到神经网络前的预处理步骤如图所示, 主要包括:
- 从原图中裁剪出或将原图调整为固定输入尺寸的图像
- 将图像由RGB色域转换到YCbCr色域, 本质上是线性变换
- 将Y, Cb, Cr通道分别通过DCT变换到频率域, 本文使用的核, 与JPEG压缩使用的是相同大小的核, 相当于过了层 channel数为 64 的 / stride 8 的卷积. 经过DCT后边长变为 , 通道数变为 64x.
- 通过动态或静态的方式选取若干通道, 拼接成一个新的tensor. 这里注意下图中 Y 通道选取了2个channel, Cb和Cr通道都只留了1个channel, 不是图画错了, 而是通道选择在3路中是独立的, 最终实验结果Y通道留下的channel更多
- 最后, 基于预计算的整个数据集统计的均值和方差去normalize每一张图
Learning-based Frequency Channel Selection
![]()
由于selection这个操作不可微, 这里使用了Gumbel Trick对selection的操作进行重参数化, 使得操作变得可微分. 该操作在NAS等领域已有很多应用, 这里就不详细说了.
需要注意的是由Tensor 3变为Tensor 4的时候, 乘以了两个可学习的参数, 来确定某一个channel保留的概率, 经过与作者确认, 这里使用一个参数也是可以实现的.
最后, loss中也加入了channel selection 的约束, 鼓励网络丢掉channel, 避免出现大量全都保留的情况.
Static Frequency Channel Selection
![]()
在输入是full channel的情况下, 训练得到模型, 然后在整个数据集上统计得到所有channel保留的概率, 得到以上的Heatmap. 可以发现:
- 保留的channel基本都是低频的
- 亮度通道Y保留的比浓度通道要多
- 对于不同的视觉任务, 保留的通道的特征差不多(上下两行差不多)
Experiment Results
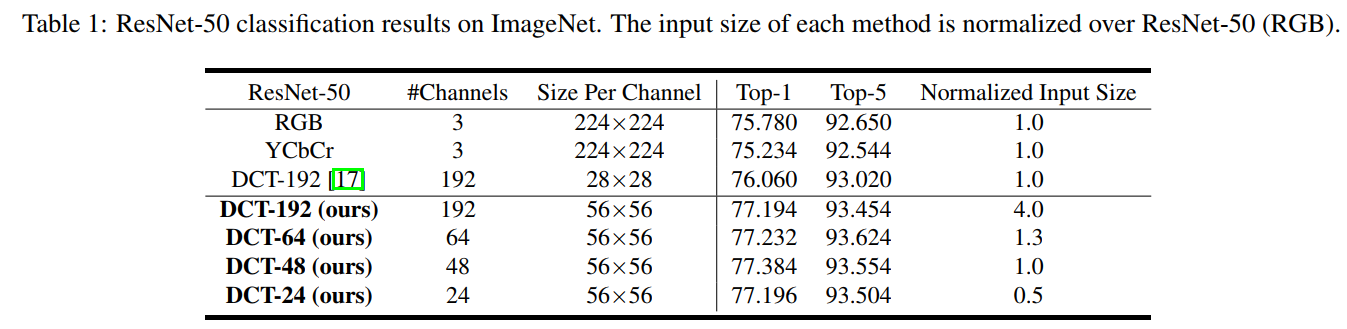
对比1,3行, 当输入是DCT-192时, Top-1提升了约 , 文中没有对此的分析, 我个人猜测是因为DCT作为一种手工设计的特征, 在这个任务中取得了比学习的方法的更好的效果. 理论上来说, 自深度网络开始流行以来, 大家都认为我们不要手工设计特征, 要让网络自动学习特征, 但网络不一定在所有情况下都能学到更好的特征. 本文这个实验结果也许就是因为引入了DCT这种具有inductive bias的特征得到的gain.
其他的结果, 文中分析得也比较清晰了, DCT-24和DCT-48也能得到和DCT-192差不多的结果, 对比通道选择的Heatmap数一数也可以知道, 如果通道低于24, 性能就要开始明显下降了.
Comments
可能有的人看完文章会觉得文中与Baseline方法的对比不够公平. 应该将Baseline的输入也扩大到4x面积, 然后接一层Conv, 再通过selection的方法丢掉一些通道. 不过这就不是本文的setting了. 本文claim的就是要输入更大的图, 通过压缩, 使得网络能够handle大的图. DCT只是一种手段, 刚刚提到的也许是另一种可行的手段. 本文不是要去说DCT比学习的特征更好, 不过如果能做一下这个分析可能会更完善.